Multi-Agent Solver-Judge with @trajectory Decorator
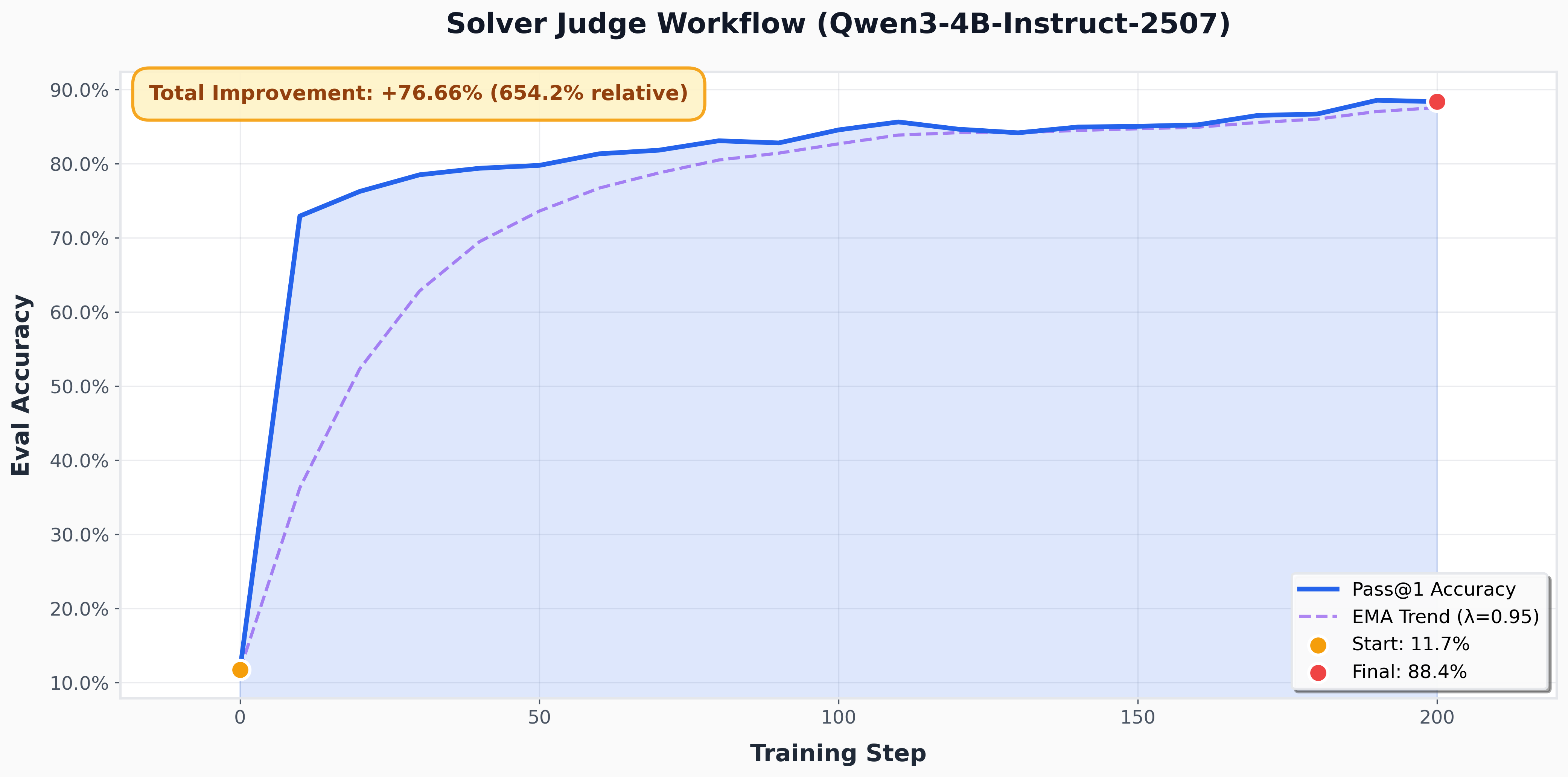
In this tutorial, you'll build a two-agent system where:
- Solver: Generates candidate solutions to a problem
- Judge: Evaluates and selects the best solution
This pattern is powerful for training agents that can both generate and verify solutions.
Overview
By the end of this tutorial, you will have:
1. Built a Solver agent that generates multiple solution candidates
2. Built a Judge agent that selects the best solution
3. Assigned separate rewards to each agent using @trajectory
4. Trained the multi-agent system end-to-end
Dataset: Countdown - Given numbers, reach a target using arithmetic operations.
Why Multi-Agent?
Training an RL agent requires two components:
- Rollout function: Perform a sequence of actions using the LLM
- Reward function: Evaluate how good the outcome is
In a multi-agent system, you have multiple rollout functions (Solver and Judge), and each gets its own reward.
Concepts
We will cover:
@trajectorydecorator: Automatic session management and trace captureTrajectoryView: Access to steps, results, and rewards- Multi-agent workflows: Composing multiple agents with independent rewards
Setup
Install rLLM if you haven't already, and prepare the Countdown dataset:
Launch a vLLM server for testing:
1. Understanding @trajectory
The @trajectory decorator automatically:
- Tracks all LLM calls as steps
- Returns a TrajectoryView with steps and result
1.1 Basic usage
from rllm.sdk import trajectory, get_chat_client_async
@trajectory(name="my_agent")
async def my_agent(prompt: str):
client = get_chat_client_async(
base_url="http://localhost:4000/v1",
api_key="EMPTY",
use_proxy=False # set to False when using vLLM server directly
)
response = await client.chat.completions.create(
model="Qwen/Qwen3-4B-Instruct-2507",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
1.2 What you get back
traj = await my_agent("What is 2+2?")
# traj is a TrajectoryView with:
print("My Agent: ", traj.name) # "my_agent"
print("Response: ", traj.result) # "4" (your return value)
print("Steps: ", traj.steps) # [StepView(...)] - one per LLM call
print("Reward: ", traj.reward) # 0.0 (default, you can set this)
2. Countdown Task
Given a target number and a list of numbers, create an equation using the given numbers to reach the target.
Example:
- Target: 150
- Numbers: [3, 50]
- Valid solution: 3 * 50 = 150
3. Build the Solver Agent
The Solver generates solution candidates for Countdown puzzles.
3.1 Define the prompt template
💡 Why
<answer>tags? The reward function looks for<answer>equation</answer>to extract the solution. Without it, the reward function cannot find your answer—similar to\boxed{}in math problems.
3.2 Define the Solver class
import asyncio
import re
from rllm.sdk import trajectory, get_chat_client_async
class Solver:
def __init__(self, use_proxy: bool = False):
self.client = get_chat_client_async(
base_url="http://localhost:4000/v1",
api_key="token-abc123",
use_proxy=use_proxy,
)
self.model = "Qwen/Qwen3-4B-Instruct-2507"
@trajectory(name="solver")
async def generate_solution(self, problem: str):
"""Generate a single solution. Returns TrajectoryView automatically."""
prompt = SOLVER_PROMPT.format(problem=problem)
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=1.0, # Higher temperature for diverse solutions
max_tokens=1000,
)
response_text = response.choices[0].message.content
return self._parse_answer(response_text)
def _parse_answer(self, response: str) -> str:
"""Extract answer from <answer>...</answer> tags."""
match = re.search(r"<answer>(.*?)</answer>", response, re.IGNORECASE | re.DOTALL)
if match:
return f"<answer>{match.group(1).strip()}</answer>"
return ""
async def generate_solutions(self, problem: str, n_solutions: int = 2):
"""Generate multiple solutions concurrently."""
tasks = [
asyncio.create_task(self.generate_solution(problem))
for _ in range(n_solutions)
]
return await asyncio.gather(*tasks)
3.4 Test the Solver
solver = Solver()
# Generate 2 solutions for a Countdown puzzle
problem = "Using numbers [3, 50], reach target 150"
trajs = await solver.generate_solutions(problem, n_solutions=2)
for i, traj in enumerate(trajs):
print(f"Solution {i+1}: {traj.result}")
print(f"Collected LLM Calls: {len(traj.steps)}")
Expected output:
Solution 1: <answer>3 * 50 = 150</answer>
Collected LLM Calls: 1
Solution 2: <answer>3 * 50</answer>
Collected LLM Calls: 1
4. Build the Judge Agent
The Judge evaluates solutions and selects the best one.
4.1 Define the Judge prompt template
The Judge needs to compare solutions and pick the correct one:
JUDGE_PROMPT = f"""You are an expert verifier. Given a countdown problem and multiple solution attempts, select a correct solution.
Problem:
{problem}
Solutions to evaluate:
{solutions}
A correct solution must satisfy the following criteria:
1. The solution uses only the given numbers.
2. Each number is used exactly once.
3. Only basic arithmetic operations (+, -, *, /) are used.
4. The calculation results in the target number.
5. The final answer is clearly marked within <answer>...</answer> tags.
Output the index of your selected solution within <answer>...</answer> tags, e.g., <answer>1</answer> for the first solution, <answer>2</answer> for the second solution, etc. If multiple solutions are correct, output the index of the first correct solution."""
4.2 Define the Judge class
class Judge:
def __init__(self, use_proxy: bool = False):
self.client = get_chat_client_async(
base_url="http://localhost:4000/v1",
api_key="token-abc123",
use_proxy=use_proxy,
)
self.model = "Qwen/Qwen3-4B-Instruct-2507"
@trajectory(name="judge")
async def judge_solutions(self, problem: str, solutions: list[str]):
"""Evaluate solutions and select the best one."""
# Format solutions list
solutions_text = ""
for i, sol in enumerate(solutions, 1):
solutions_text += f"\nSolution {i}:\n{sol}\n"
prompt = JUDGE_PROMPT.format(problem=problem, solutions=solutions_text)
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=1.0,
max_tokens=2000,
)
response_text = response.choices[0].message.content
return self._parse_selection(response_text, solutions)
def _parse_selection(self, response: str, solutions: list[str]) -> str:
"""Extract selected solution index."""
match = re.search(r"<answer>(\d+)</answer>", response)
if match:
idx = int(match.group(1)) - 1
if 0 <= idx < len(solutions):
return solutions[idx]
return ""
4.3 Test the Judge
judge = Judge()
solutions = [
"<answer>3 * 50 = 150</answer>",
"<answer>Wrong answer</answer>"
]
judge_traj = await judge.judge_solutions(problem, solutions)
print(f"Selected: {judge_traj.result}")
print(f"Steps: {len(judge_traj.steps)}")
Expected output:
5. Compose the Workflow
Now combine Solver and Judge, assigning rewards to each trajectory.
from rllm.sdk import TrajectoryView
from rllm.rewards.countdown_reward import countdown_reward_fn
class SolverJudgeWorkflow:
def __init__(self, n_solutions: int = 2, **kwargs):
self.n_solutions = n_solutions
self.reward_function = countdown_reward_fn
self.solver = Solver(use_proxy=True)
self.judge = Judge(use_proxy=True)
async def run(self, task: dict, **kwargs) -> list[TrajectoryView]:
"""Run the full workflow and return all trajectories."""
problem = task["question"]
# Step 1: Generate multiple solutions
solver_trajs = await self.solver.generate_solutions(problem, self.n_solutions)
# Step 2: Assign rewards to each solver
solutions = []
for traj in solver_trajs:
parsed_answer = traj.result
reward = self.reward_function(task, parsed_answer).reward
# Assign reward to the trajectory AND its steps
traj.steps[0].reward = reward
traj.reward = reward
solutions.append(parsed_answer)
# Step 3: Judge selects the best solution
judge_traj = await self.judge.judge_solutions(problem, solutions)
selected = judge_traj.result
# Judge reward based on final selection quality
judge_reward = self.reward_function(task, selected).reward
judge_traj.steps[0].reward = judge_reward
judge_traj.reward = judge_reward
# Return ALL trajectories for training
return solver_trajs + [judge_traj]
5.3 Reward assignment strategy
Example run:
┌─────────────────────────────────────────────────┐
│ Problem: Reach 150 with [3, 50] │
├─────────────────────────────────────────────────┤
│ Solver 1: "100 + 50 = 150" → reward = 0.0 ✗ │
│ Solver 2: "3 * 50 = 150" → reward = 1.0 ✓ │
│ Judge: selects Solver 1 → reward = 1.0 ✓ │
└─────────────────────────────────────────────────┘
Training signal:
• Solver 2 is reinforced (correct answer)
• Solver 1 learns to improve (wrong answer)
• Judge learns to identify correct solutions
6. Set Up Training
6.1 Create the training wrapper
import hydra
from rllm.data.dataset import DatasetRegistry
from rllm.trainer.agent_trainer import AgentTrainer
async def run_workflow(**kwargs) -> list[TrajectoryView]:
"""Training wrapper that returns trajectories."""
workflow = SolverJudgeWorkflow(
n_solutions=2,
)
return await workflow.run(kwargs)
@hydra.main(
config_path="pkg://rllm.trainer.config",
config_name="agent_ppo_trainer",
version_base=None
)
def main(config):
train_dataset = DatasetRegistry.load_dataset("countdown", "train")
test_dataset = DatasetRegistry.load_dataset("countdown", "test")
trainer = AgentTrainer(
config=config,
train_dataset=train_dataset,
val_dataset=test_dataset,
agent_run_func=run_workflow,
)
trainer.train()
if __name__ == "__main__":
main()
6.2 Launch script
#!/bin/bash
# train_decorator.sh
set -x
export VLLM_ATTENTION_BACKEND=FLASH_ATTN
export PYTORCH_CUDA_ALLOC_CONF="expandable_segments:False"
export VLLM_USE_V1=1
export VLLM_ALLOW_LONG_MAX_MODEL_LEN=1
export VLLM_ENGINE_ITERATION_TIMEOUT_S=100000000000
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python3 -m examples.sdk.solver_judge.train_solver_judge \
data.train_batch_size=64 \
data.max_prompt_length=2048 \
data.max_response_length=1024 \
actor_rollout_ref.model.path=Qwen/Qwen3-4B-Instruct-2507 \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.loss_agg_mode=seq-mean-token-mean \
actor_rollout_ref.actor.use_dynamic_bsz=True \
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=32768 \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.use_kl_loss=False \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0.0 \
actor_rollout_ref.actor.clip_ratio_low=0.2 \
actor_rollout_ref.actor.clip_ratio_high=0.28 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=True \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
actor_rollout_ref.actor.ulysses_sequence_parallel_size=1 \
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.mode="async" \
actor_rollout_ref.rollout.enforce_eager=False \
actor_rollout_ref.rollout.temperature=1.0 \
actor_rollout_ref.rollout.top_p=1.0 \
actor_rollout_ref.rollout.gpu_memory_utilization=0.85 \
actor_rollout_ref.rollout.n=4 \
actor_rollout_ref.rollout.val_kwargs.n=1 \
actor_rollout_ref.rollout.val_kwargs.temperature=1.0 \
actor_rollout_ref.rollout.val_kwargs.top_p=1.0 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.adv_estimator=grpo \
rllm.compact_filtering.enable=False \
rllm.compact_filtering.mask_max_prompt_length_exceeded=True \
rllm.compact_filtering.mask_max_response_length_exceeded=True \
rllm.compact_filtering.mask_max_turns_exceeded=False \
rllm.compact_filtering.mask_timeout=True \
rllm.rejection_sample.enable=False \
rllm.rejection_sample.multiplier=1.0 \
rllm.stepwise_advantage.enable=True \
rllm.stepwise_advantage.mode=per_step \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name='sdk-solver-judge' \
trainer.experiment_name='sdk-solver-judge' \
trainer.val_before_train=False \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=200 \
trainer.test_freq=10 \
trainer.total_epochs=100 \
rllm.sdk.proxy.host=127.0.0.1 \
rllm.sdk.proxy.port=4000 \
rllm.sdk.proxy.mode=subprocess \
rllm.sdk.store.path="$/tmp/rllm-traces.db"
7. Run Training
Next Steps
- Tutorial 1: Review the basics with a single-step agent
- Tutorial 3: Train a LangGraph RAG agent with tool use